
dbForge SQL Complete
Accelerate your SQL coding with advanced add-in for SSMS and VS
Download now
Free edition available
The difference between UNION and UNION ALL lies in how duplicates are handled. UNION combines the results of two or more SELECT statements and removes duplicate rows, while UNION ALL returns every row, including duplicates.
In other words, SQL UNION syntax requires the same number of columns, in the same order, with compatible data types, and produces a distinct result set.

SQL Server enforces strict rules on column data types when you use UNION or UNION ALL. Each SELECT in the query must return the same number of columns, and the columns are matched by position, not by name. The data types in those positions must be compatible so that SQL Server can implicitly convert them to a common type.
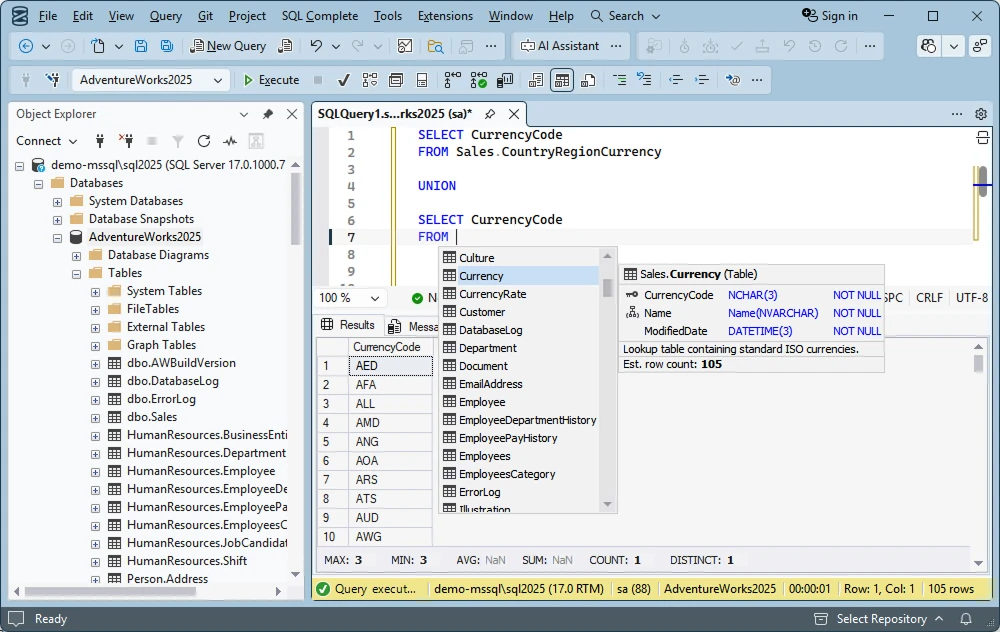
Compatible types example
SELECT CAST(100 AS INT)
UNION
SELECT CAST(250.75 AS DECIMAL(10,2));Here, INT is automatically converted to DECIMAL, so the query runs without issue.
Incompatible types example
SELECT 'SampleText'
UNION
SELECT GETDATE();
This query fails because SQL Server tries to implicitly convert the string to DATETIME, but SampleText is not a valid date/time value, so the conversion fails and an error is raised.
Msg 241, Level 16, State 1, Line 1
Conversion failed when converting date and/or time from character string.Key takeaway
When combining queries with UNION or UNION ALL, always make sure that:
This prevents conversion errors and keeps your queries predictable.
Let's look at how UNION functions in SQL. The syntax for it is as follows:
SELECT column_1, column_2, ... column_n
FROM table_1
UNION
SELECT column_1, column_2, ... column_n
FROM table_2
...
UNION SELECT column_1, column_2, ... column_n
FROM table_N;
Dealing with UNIONs might not be so easy for inexperienced users, you need to clearly understand how the operator works and remember the names of the columns you want to combine. That's where dbForge SQL Complete can give a helping hand.
As part of our SQL UNION operator tutorial, we will explain UNIONs with the examples presented in the dbForge SQL Complete tool and try to cover the difference between UNION and UNION ALL in SQL.
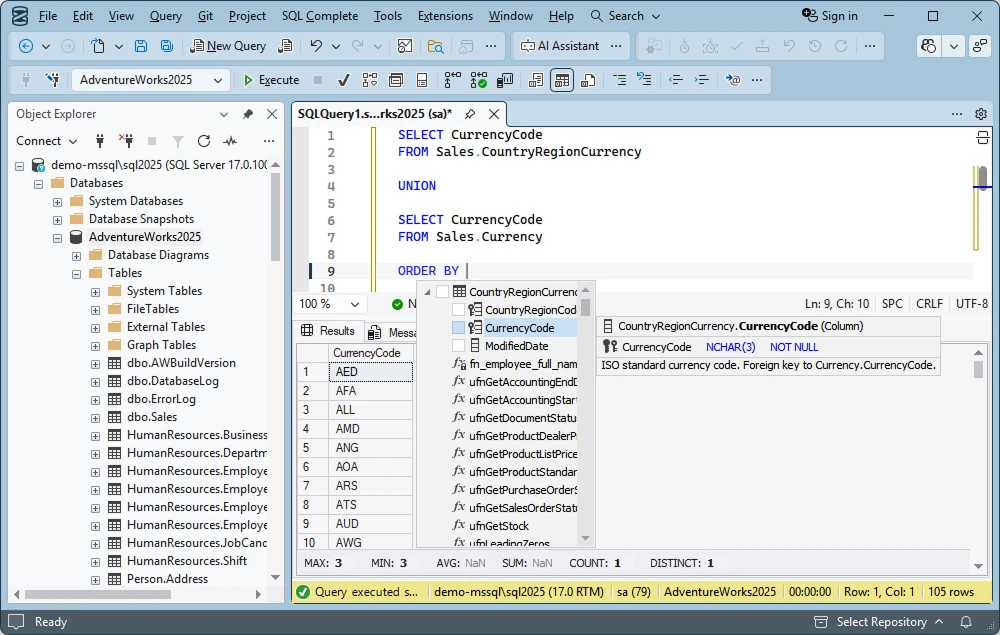
Suppose, we have the customerdemo database with the Employee table in it. The table contains ten records. We want to find out the ids of managers to whom the employees whose last names begin with 'S' and 'T' report to. In the output you can see two ids.
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'S%'
UNION
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'T%'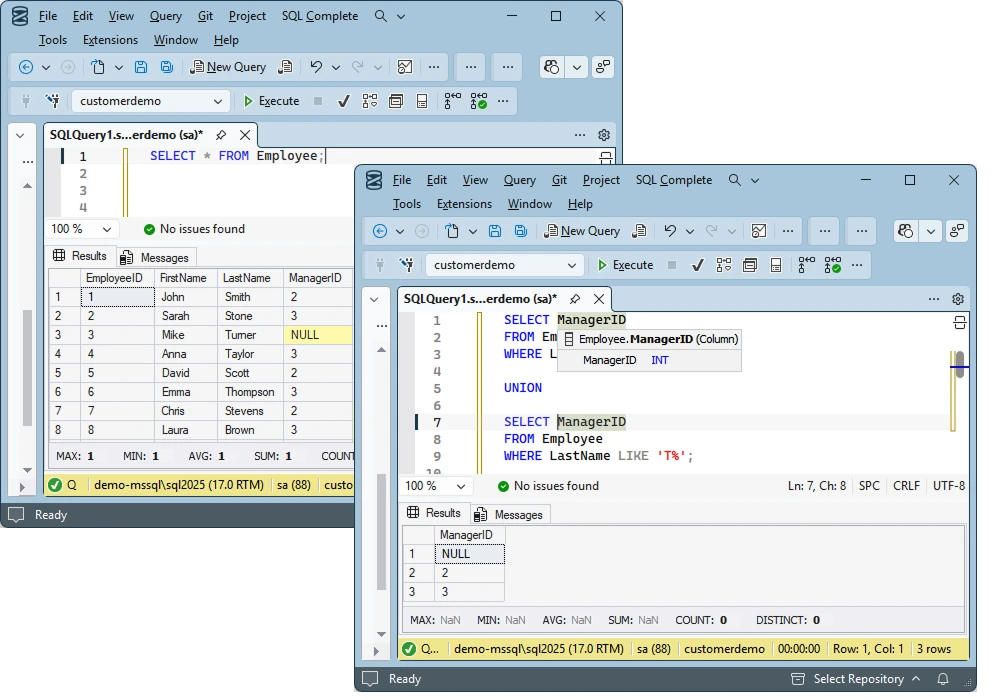
A key difference between UNION and UNION ALL is how they treat NULL values. In SQL Server, NULL is considered equal to another NULL when removing duplicates.
Suppose we have the following two queries on an Employee table where some managers are unknown (NULL).
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'S%'
UNION
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'T%';Result (UNION)
| ManagerID |
|---|
| NULL |
| 1 |
| 2 |
Now compare with UNION ALL.
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'S%'
UNION ALL
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'T%';Result (UNION ALL)
| ManagerID |
|---|
| NULL |
| 1 |
| NULL |
| 2 |
In the UNION query, only one NULL is kept. In the UNION ALL query, both NULL values are returned.
Takeaway: If duplicates, including NULLs, are meaningful for your analysis, use UNION ALL.
You can also use UNION and UNION ALL to combine the results of subqueries. This is useful when you need to apply filters, perform aggregations, or work with derived data before merging it into a single result set.
Basic syntax
SELECT subquery_alias.column
FROM (subquery_1) AS subquery_alias
UNION [ALL]
SELECT subquery_alias.column
FROM (subquery_2) AS subquery_alias;Common use cases:
Suppose we have a Sales table with columns Region, OrderDate, and Amount. We want to compare total sales for two different regions. By wrapping each query in a subquery, we can aggregate results separately and then combine them into a single dataset.
SELECT Region, TotalSales
FROM (
SELECT 'North' AS Region, SUM(Amount) AS TotalSales
FROM Sales
WHERE Region = 'North'
) AS NorthSales
UNION
SELECT Region, TotalSales
FROM (
SELECT 'South' AS Region, SUM(Amount) AS TotalSales
FROM Sales
WHERE Region = 'South'
) AS SouthSales;Result
| Region | TotalSales |
|---|---|
| North | 125000 |
| South | 98000 |
This approach allows you to work with aggregated subquery results and present them as a single, combined dataset.
The SQL Server UNION ALL operator allows combining the results of two or more SELECT statements. It returns all rows from the query and does not eliminate duplicate rows.
Generally, the UNION ALL command is quite similar to the UNION command. The only difference is that UNION ALL selects all values. In other words, UNION ALL will not remove duplicate rows. Instead, it will fetch all rows matching the query and combine them in a result table.

The T-SQL syntax for UNION ALL is as follows:
SELECT
column_1, column_2, ... column_n
FROM table_1
UNION ALL
SELECT column_1, column_2, ... column_n
FROM table_2
...
UNION ALL
SELECT column_1, column_2, ... column_n
FROM table_N;
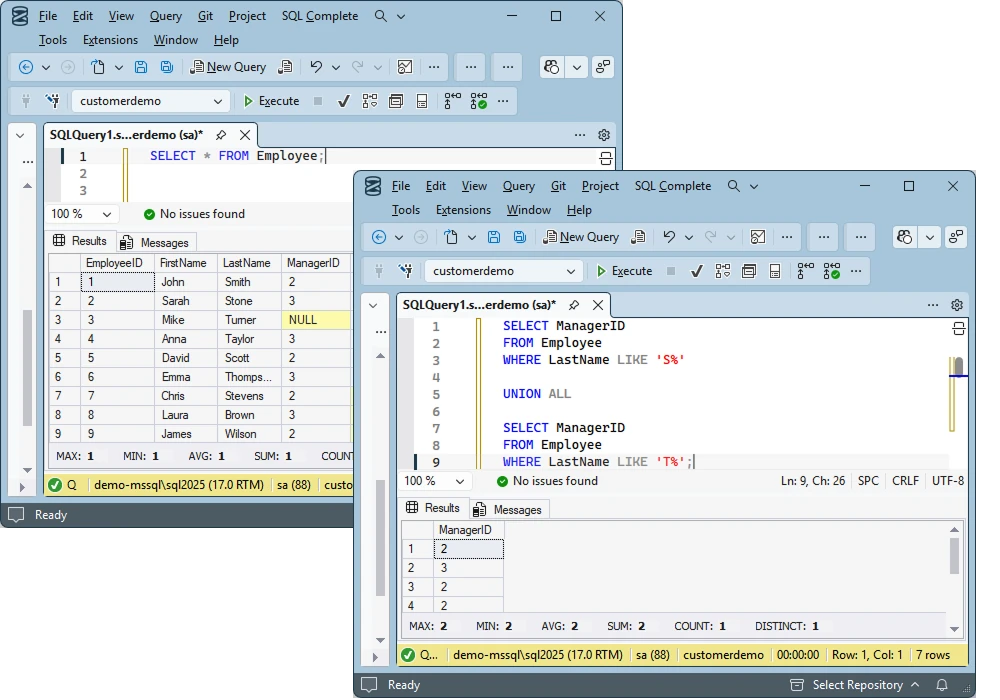
Let's now look at how to use SQL UNION ALL.
Remember that Employees table we have discussed earlier? Let's run UNION ALL against it.
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'S%'
UNION ALL
SELECT ManagerID
FROM Employee
WHERE LastName LIKE 'T%'As you can see from the result in the output, UNION ALL, as we mentioned earlier, doesn't remove duplicates from the result set.
As we have already mentioned, UNION returns only distinct records, while UNION ALL returns all the records retrieved by queries. If we speak about SQL Server UNION vs UNION ALL performance, UNION ALL gives better performance in query execution as it does not waste resources on removing duplicate rows.
Let's look at the difference using SQL Server execution plans.
You can see that the estimated cost of the UNION ALL query is significantly lower, while UNION has an additional Sort operation, and the large amount of resources is spent on this operation.
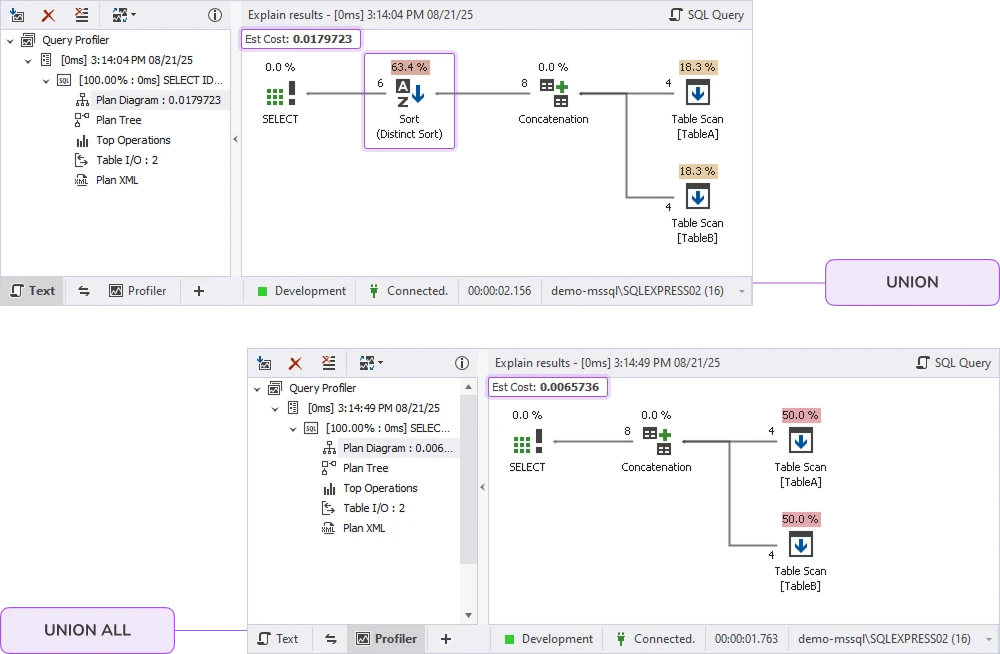
To see how this works in practice, here's what the execution plans show:
The following table summarizes the main differences at a glance.
| Operation | UNION | UNION ALL |
|---|---|---|
| Removes Duplicates | Yes | No |
| Requires Sorting | Yes | No |
| Performance | Slower | Faster |
| Memory Usage | Higher | Lower |
To improve performance, consider using SQL UNION ALL when duplicates are acceptable. Beyond execution time, UNION and UNION ALL also differ in how they use memory on large datasets.
On large tables, the performance gap between UNION and UNION ALL becomes significant. The reason lies in how SQL Server processes duplicates.
-- Using UNION
SELECT CustomerID FROM Orders_2024
UNION
SELECT CustomerID FROM Orders_2025;
-- Using UNION ALL
SELECT CustomerID FROM Orders_2024
UNION ALL
SELECT CustomerID FROM Orders_2025;In the execution plan:
Takeaway: When duplicates are acceptable, use UNION ALL. It scales better on large datasets by avoiding unnecessary sorting, reducing memory grants, and lowering the chance of spills to tempdb.
You cannot use the ORDER BY clause with each SELECT statement in the query. SQL Server can perform sorting only on the final result set.
If you try running a query with the ORDER BY clauses on multiple SELECT statements, you will get the 'Incorrect syntax' error. The SQL syntax for UNION with ORDER BY is as follows:
SELECT column_name
FROM table_1
UNION | UNION ALL
SELECT column_name
FROM table_2
ORDER BY
order_by_expression;
UNION and UNION ALL allow combining two or more SELECT statements with their WHERE clauses. However, you need to make sure that the number and order of columns in all queries are the same, and that their datatypes are compatible.
SELECT column_1, column_2
FROM table_1
WHERE condition
UNION | UNION ALL
SELECT column_1, column_2
FROM table_2
WHERE condition;
When combining queries with UNION or UNION ALL, SQL Server aligns columns by position, not by name. This means the first column in the first query will be matched with the first column in the second query, regardless of their names.
If the column names differ, you can use aliases to make the output more readable and avoid confusion. The final result set will use the column names from the first query.
Suppose we have two tables:
SELECT CustomerID AS ClientID
FROM Customers
UNION
SELECT BuyerID AS ClientID
FROM Orders;Result
| ClientID |
|---|
| 101 |
| 102 |
| 205 |
Here, CustomerID and BuyerID are aligned by position. By applying the alias ClientID, the final output has a consistent column name.
| Feature | UNION | UNION ALL |
|---|---|---|
| Duplicate rows | Removed automatically | Included in the final result |
| Performance | Slower due to duplicate elimination | Faster since it skips duplicate checks |
| Sorting/Filtering | Performs an implicit sort to remove duplicates | No sorting unless explicitly requested |
| Result set size | May be smaller than the sum of all queries | Always equals the total of all queries |
| Use case | When you need distinct records | When all data (including duplicates) matters |
| System resource usage | Higher (CPU/memory) | Lower, especially with large datasets |
| Typical scenario | Combining lookup data without repetition | Merging logs, transactions, or audit data |
Both JOIN and UNION combine data, but they do so in very different ways.
It should be mentioned that JOINs and UNIONs have two absolutely different purposes. JOINs are used to form a new result table by combining columns from two or more tables. UNIONs, however, are used to combine the results of two distinct queries with the same columns, appending the result rows together row by row.
To make the distinction clearer, think of the operations like this:

The primary difference between these operators is that UNION removes duplicate rows from the combined result set, while UNION ALL includes all rows from the query output, including duplicates.
UNION ALL is generally faster than UNION because it does not sort the result set and does not remove duplicate rows from it.
UNION ALL is the preferred option when duplicates are meaningful or acceptable. For instance, data aggregation, audit trails, or performance-sensitive operations may benefit from using the UNION ALL operator.
UNION is the preferred option when your work scenario requires eliminating duplicate rows.
Most SQL dialects support both UNION and UNION ALL. Still, syntax rules (such as parentheses, column aliasing, and ordering) may vary slightly across platforms, including MySQL, PostgreSQL, Oracle, and SQL Server, which can affect how queries are written. Ensure that your query is correctly adjusted to the specific SQL dialect.
UNION automatically removes duplicate rows from the combined result by comparing all selected columns and returning only distinct records.
The most common mistakes occur when there is a mismatch between column counts or data types in queries, or when the column aliases are incorrect, or when UNION is used instead of UNION ALL (and vice versa).
UNION ALL is more efficient for handling large datasets because it skips the extra step of checking for and removing duplicates. As a result, it offers faster performance, produces a lighter query, and is well-suited for merging large volumes of data, provided that duplicate records in the output are acceptable.
Yes, each SELECT statement in a UNION or UNION ALL query can have its WHERE clause. It allows you to implement specific filtering before applying UNION.
It depends on the reporting needs. If you need distinct records only, use the UNION operator. However, if performance is a concern, UNION ALL is preferable as it does not expend resources on removing duplicate entries. Of course, using UNION ALL is suitable only if your use case allows duplicate records in the report.